音声対話と意図抽出
-情報支援のための音声対話システムと意図抽出技術
について-
背景と目的
高齢者の情報支援を行うロボットシステムを開発するために, 音声対話システムをロボットに実装する必要がある. しかし, 現状の音声認識技術では, 軽度認知症者を含む高齢者との対話中の音声を正確に認識することは困難である. そのため, 高齢者の発話の特徴に対応可能な認識手法を開発するとともに, 生活環境における雑音への対策が必要になる. また, 発話内容をテキスト化した文章を得ることを目指すのではなく, 対話の進行に必要な情報を取り出すことを目的として, 発話全体の特徴から意図を抽出して識別する手法を開発した.
手法
高齢者の発話の特徴に対応するため手法としては, 一般的な音声認識技術として, 話者の特徴に合わせて音声認識モデルを修正する話者認識技術が用いられる. また, 雑音に対応する技術として, 特定方向からの音を強調するマイクアレイ技術や, 背景雑音の特徴を学習して除去する技術などが一般的である. さらに平均的な音声モデルとは異なる発声に対応するため, 一般的な発音表記による単語辞書に基づく手法でなく, 表記のゆれにも対応可能なサブワード単位の音声認識技術を用いた. それでも, 自発的な対話音声を正確に認識することは困難であるため, 発話内容のテキスト化を目指すのではなく, 対話の進行に必要な意図のカテゴリを設定し, 発話全体のサブワード系列から意図のカテゴリを識別する手法を開発した. さらに意図の識別精度を向上させるために, 言語的情報だけでなく韻律的特徴を利用したり, 認識結果や個人の特性に応じて対話の進行を動的に制御する対話プラニング技術を開発した. また, 実際の生活現場での実証実験を通じて, ロボットの発話の途中での割り込みによる認識誤りが多いことが判明したため, 割り込み発話の認識にも対応可能なバージイン技術も採り入れた.

実装例
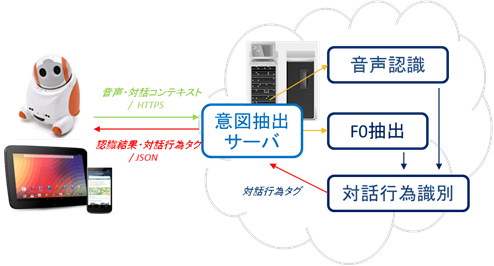
意図抽出技術を含む対話システムの実装例を下図に示す. 意図抽出モジュールをクラウドサーバ上に実装し, 端末で取得された音声は HTTPS プロトコルにより暗号化してサーバに送信される. サーバにおいては, まず, 音声認識と基本周波数(F0)の抽出が行われ, これらの情報に基づいて, 対話における発話の機能を表す対話行為タグが識別される. ここで用いるタグは, 情報支援という我々のタスクを考慮して, 情報要求, 確認要求, 行為要求, 注目要求, 言い直し要求, 肯定的返事, 否定的返事, 情報提供, あいさつ, あいづち(承認), あいづち(不承認), その他の12種類を用意した. 得られた対話行為タグは, 音声認識結果とともにJSON形式で端末に送信され, 端末上の対話管理モジュールが対話を制御するために用いられる.
改良
開発の過程で音声認識精度向上のために手法の改良を行なった. 通常用いられるトライフォンよりも時間粒度の大きい, モーラと音韻環境依存モーラを認識ユニットに用いることで, 瞬時特徴よりも, 特徴の時間変化を重視した音響モデルを開発した. 取り扱いの容易さも考慮して, ユニット毎に7個から13個の状態を持ち, 各状態で64混合の正規分布を持つモーラ音響モデルを現在は用いており, 59%の音素正解精度を確保することができた. また, より計算コストを抑えてタグの識別を行うために, 直前の対話コンテキストを考慮したベイズ識別器を開発した. この識別器は, 並列計算を用いることなく高速に識別を行うことができるが, ギャップを含むサブワード系列の分析ができないために, 識別精度が若干低下するが, この時点で77%程度の識別精度が得られた. さらに, 情報要求や言い直し要求など, 疑問文の対話行為識別精度を向上させるために, 音声の基本周波数の変化を利用する識別モデルの開発を行った. 疑問文の文末にかけて基本周波数F0が高くなる傾向に着目して, 文中のF0の変化を特徴として用いることで, 対話行為タグの識別精度の向上を試みたが効果を確認することはできなかった. その理由として, 自由発話においては, そもそも文の境界が不明瞭であることに加えて, 認識誤りが多いために, 文を正しく抽出することが難しいことが考えられた. そこで, F0の変化を文の特徴としてではなく, フレーズ特徴とするモデル化を行った. 具体的には, 単語やサブワードの任意のNグラムに対して, F0の増加, 減少, 変化なしの3値の極性を付与し, この極性付きのNグラムを用いて対話行為の識別を行った. その結果, 高齢者音声対話コーパスにおいて, 全体で1%弱, 個別の対話行為では, 情報要求と言い直し要求においてそれぞれ4%と10%, 適合率を向上できることが分かった.
実証実験
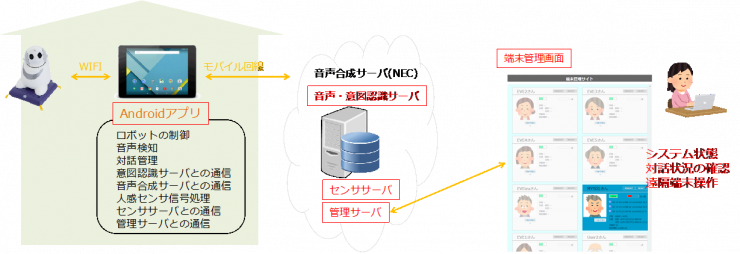
ロボットによる情報支援の有効性と効果検証のため, 実際の高齢者住宅に長期間設置して実証実験を行なった. システムの概要を下図に示す. ここで得られたデータに基づいてシステムの評価と改良を進めた. 予備実験で取得した3,308発話のうち, 被験者毎におよそ200発話を評価データとし, 残り2,109発話を訓練データとして用いて, 言語モデルと意図タグ識別モデルの適応を行った結果, モーラ単位の音声認識精度は9.6%, 意図タグの識別精度は13.9%性能が向上し, 意図抽出の平均識別精度58.3%で, 音声検知の間違いを除くと68.4%であった.
さらに効果検証実験を進め, 被験者6名に対して各々4週間実施した情報支援1,749回分を書き起こし, 実際に被験者が応答した1,145回から, 4,458発話を抽出し, 音声検知モジュールと意図抽出モジュールの性能分析を行った結果, 音声検知の平均検出率は68.8%, 平均検出精度は85.9%であった. その後も実験を進め, 8名の被験者に対して延べ40ヶ月の音声対話データを取得した.
このうち, 音声検知性能が低かった被験者に対して, テレビなどの雑音に対応するために, 下の写真のように4chマイクロホンアレイを利用したシステムを開発した. これを1ヶ月適用し, マイクロホンアレイの効果を検証した. ここでは, 日中ほぼテレビがついているため, テレビ音声の誤検出が多く, これまで音声検出精度が 45.1%にとどまっていた. さらに, ロボットの発話完了を待たずに回答するために検出漏れが多く, 音声検出率が 39.9% とかなり低くいという問題があった. 音声検出精度の問題に対しては, マイクロホンアレイから得られる音源方向情報を用いて, ロボットの正面 90 度以外から到来する音声をノイズとみなすことで, 検出精度は 95.0%まで高まった. 音声検出率の問題に対しては, エコーキャンセラにより, ロボット自身の発話を抑圧した上で, ロボットの発話最後の1秒との重複を許した音声検知アルゴリズムを実装することで 64.5%まで音声検出率が改善した. 検出漏れが生じた原因を分析したところ, テレビの影響を受けたと思われる発話が 45%, ロボットの発話と被る等, 音声検知のタイミングとずれて発話されたものが 37%, 声が遠いことによる検出漏れが 13%であった.

今後の課題
近年は, スマートホンや音声アシスタント端末などによる音声対話システムの普及が進み, 手法的にも大量のデータからの深層学習により精度の向上が急速に進んでいるが, 実際の高齢者が長期間利用するには, まだまだ多くの課題が残っている. 本件の事例のように, 長期間の実証実験により課題を抽出し, 個別に対応と改良を進めていくことが今後も重要になる.
参考
[1] 児島宏明,佐土原健,他,「認知症者を対象とした情報支援ロボットとの対話における相槌の認識」,日本音響学会秋季研究発表会講演論文集,pp. 437-438,2011-09.
[2] 佐土原健,児島宏明,他,「認知症者とロボットの対話のための相槌認識における話者依存性の分析と話者適応の効果について」,電子情報通信学会技術研究報告,SP2011-62,pp. 61-66,2011-10.
[3] 佐土原健,児島宏明,他,「軽度認知症高齢者のための情報支援システムにおける不適格発話に頑健な談話行為識別」,人工知能学会 言語・音声理解と対話処理研究会,2012-11.
[4] Ken Sadohara et. al.: Sub-lexical dialogue act classification in a spoken dialogue system support for the elderly with cognitive disabilities, Workshop on Speech and Language Processing for Assistive Technologies, Grenoble (France), 2013-08-21.